Slate Tech Stack
Frontend
Slate v3 (Current)
Slate is based around AngularJS 1.x. For styling it uses bootstrap 3.x with custom themeing. Many UI components are based on angular-ui-bootstrap
Gulp has been implemented as the build system.
Slate v4 (In Development)
Slate v4 is built around Vue 3. Styling will continue to be built around Bootstrap, upgraded to v5. UI components are being ported from angular-ui (MIT licensed) where needed.
The build system is Vite.
Backend
API
The Slate API is a Django 3.2 application. The API interface leverages parts of the Django Rest Framework (DRF).
Work is currently underway to port custom view classes to use DRF generic views with reusable filtering, pagination, etc.
Task Queue
The task queue is currently Celery, backed with a redis broker. Previously RabbitMQ was used, but consistent issues caused us to switch brokers. Redis was chosen for the message broker, as it was already being used for a caching layer.
In the near we will be switching from Celery to Huey for our task queue. Over time Celery has proven overly complex for our requirements.
Caching
We use the built in Django caching functionality in various places. Mainly to reduce expensive processes which don't change often. Examples include auth tokens for file storage, permission sets, etc. Care is taken to invalidate when needed, or to expire before refresh would be required.
API results are not cached server side. Caching results has reduced benefits due being behind authentication, requiring per user caching. Browser caching is often sufficent to stop excessive refetching of data.
Database
Currently our database is MySQL 8.x. Originally MySQL was chosen due to us already having a working instance.
Slate has been tested, and is functional on PostgreSQL. We are evaluating the feasibility of switching an exsting deployment of Slate.
Any database caching is handled on an as needed basis in the Slate API.
Error Reporting
We use Sentry for live error tracking.
Server Architecture
Hosting
Our current hosting is provided by Rackspace. Each Slate deployment is a permanent VM and Hosted MySQL Database. File storage is based on Rackspace Files.
Slate has been succesfully tested to run on Digital Ocean, with a hosted PostreSQL instance, and using Spaces as a file store. Slates file storage backend is a 'pluggable' interface, and can be switched out. Plans are in process to move all hosting to Digital Ocean, due to cost, feature set, and performance.
The Slate API lives behind an Nginx reverse proxy. Nginx serves the built Slate frontend, and proxies to the API.
Scalability
Scaling Slate can be done in several ways, depending on the bottleneck.
The Slate API can be scaled horizontally, adding additional servers pointed at the same backend. With a loadbalancer in front, this will spread the load, reducing CPU bottlenecks
Database bottlenecks can be reduced by adding a read-replica. Django can be configured to use multiple databases, and slate could be changed to take advantage of a read-replica for any non-destructive calls. Such as list views, or complex reporting.
File storage is already scaled, using object storage. Rather than a black storage with a defined container size, object storage isn't limited in storage size by definition.
If the task queue is consistently unable to keep up, additional workers can be added. Workers would scale horizontally similar to the API.
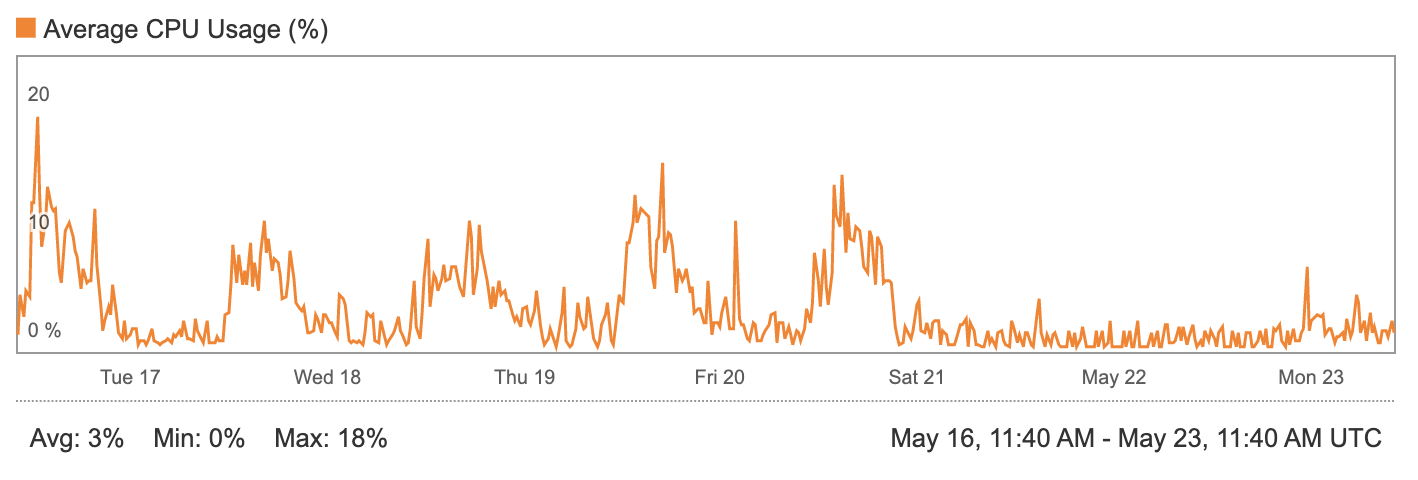
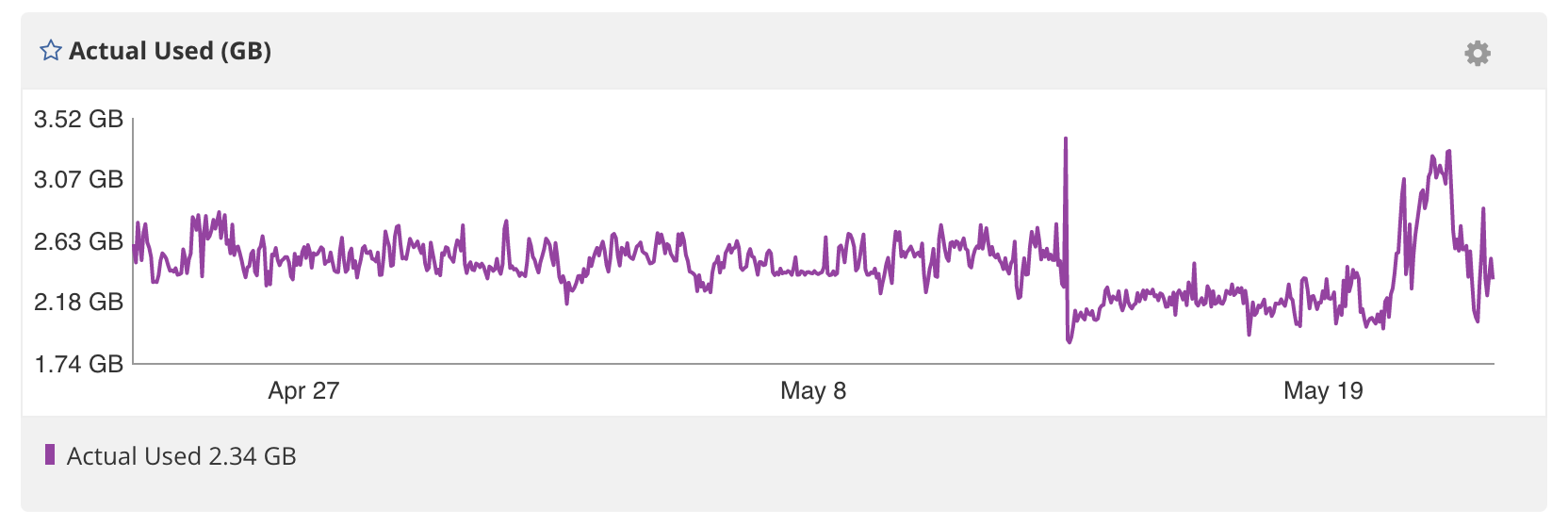
Currently the production version of Slate is under-utilizing a single server. Due to recent optimization, we'ver reduced the server requirements. The main culprate having been Celery and RabbitMQ. The current server runs the Slate API, task worker, Nginx, and Redis, with room to spare. The specific server has 8 threads, and 8gb of ram. Slate's disk space usage on the server is negligable.
With the move to Digital Ocean, we expect to be able to vastly downscale the production server, furtur reducing costs.
Slate's configuration is currently provided through either a .env file, or through environment variables. This allows it the be run in a Docker container if desired. However we've found the work involved not to have a significant return on the time investment. We do not expect a more in depth solution like Kubernetes to be worthwile at this time.